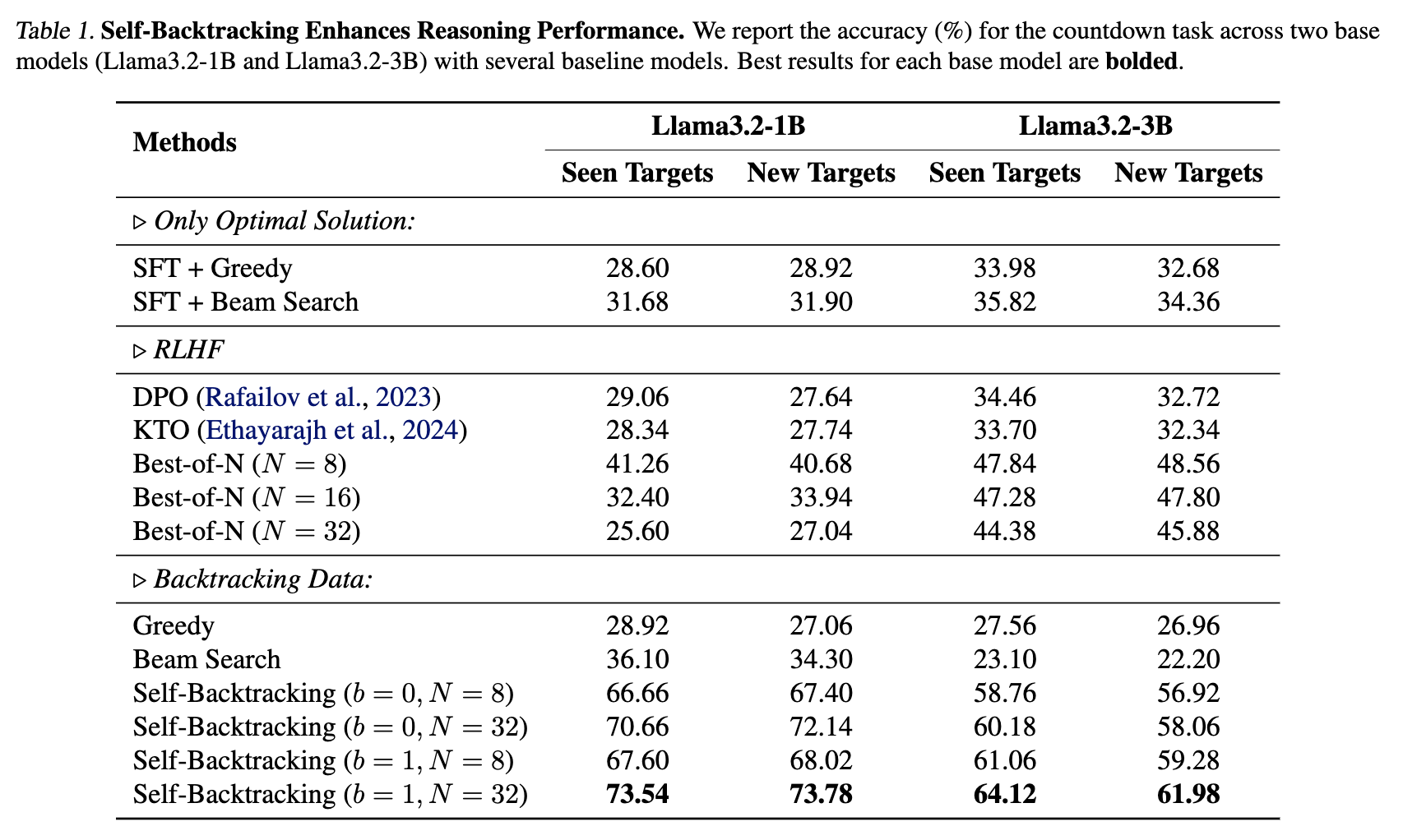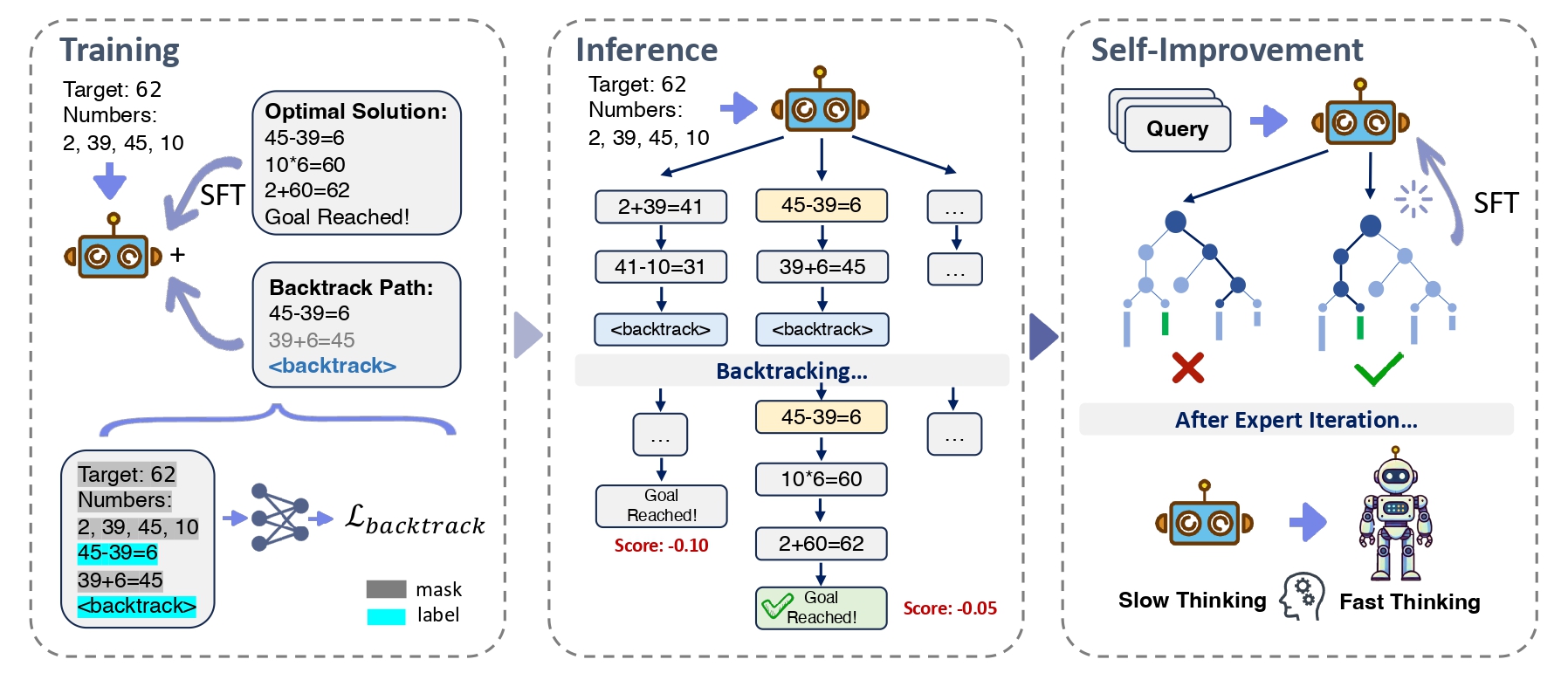
Under the standard Supervised Fine-Tuning (SFT) framework, we typically employ a dataset \(\mathcal{D}_{op} = \{(x_i, y_i)\}_{i \in [n_{op}]}\), where for reasoning tasks, \(y_i\) represents the natural language reasoning path representing the optimal solution. To enable the model to backtrack at appropriate times and positions, we introduce a backtracking dataset: \[\mathcal{D}_{back} = \{\left(x_j, \texttt{prefix}(y_j) \circ a_{err} \circ \langle \texttt{backtrack} \rangle\right)\}_{j \in [n]}.\] Here, \(\texttt{prefix}(y_j)\) denotes the prefix of the optimal solution \(y_j\), representing a partial solution; \(a_{err}\) signifies an erroneous action extended from the partial solution, which cannot lead to the correct answer; and \(\langle \texttt{backtrack} \rangle\) is a special token indicating that the model needs to backtrack from the current state. The final dataset is \(\mathcal{D}=\mathcal{D}_{op}\cup\mathcal{D}_{back}\).
Our self-backtracking technique consists of three main phases:
1. Training Phase
We train the model using a combination of optimal solution data and backtracking data:
The training loss function consists of two components: the supervised fine-tuning (SFT) loss and the backtracking loss. The backtracking dataset is constructed to help the model learn when and where to backtrack by introducing erroneous actions and a special backtrack token.
The backtracking loss function, \(\mathcal{L}_{backtrack}(\theta)\), is crucial for training the model to recognize when its current reasoning path is suboptimal and to backtrack to explore alternative paths. It consists of two main components:
- Partial Solution Prediction: This component encourages the model to predict partial solutions accurately given the input, ensuring that the model can generate correct reasoning steps up to a certain point.
- Backtrack Token Prediction: This component focuses on the model's ability to predict the \(\langle \texttt{backtrack} \rangle\) token when it has deviated from the correct path. This helps the model learn to identify erroneous actions and backtrack appropriately.
Here, \(\texttt{prefix}(y_j)\) represents a partial solution, and \(a_{err}\) is an erroneous action. The \(\langle \texttt{backtrack} \rangle\) token indicates that the model should backtrack from the current state.
2. Inference Phase
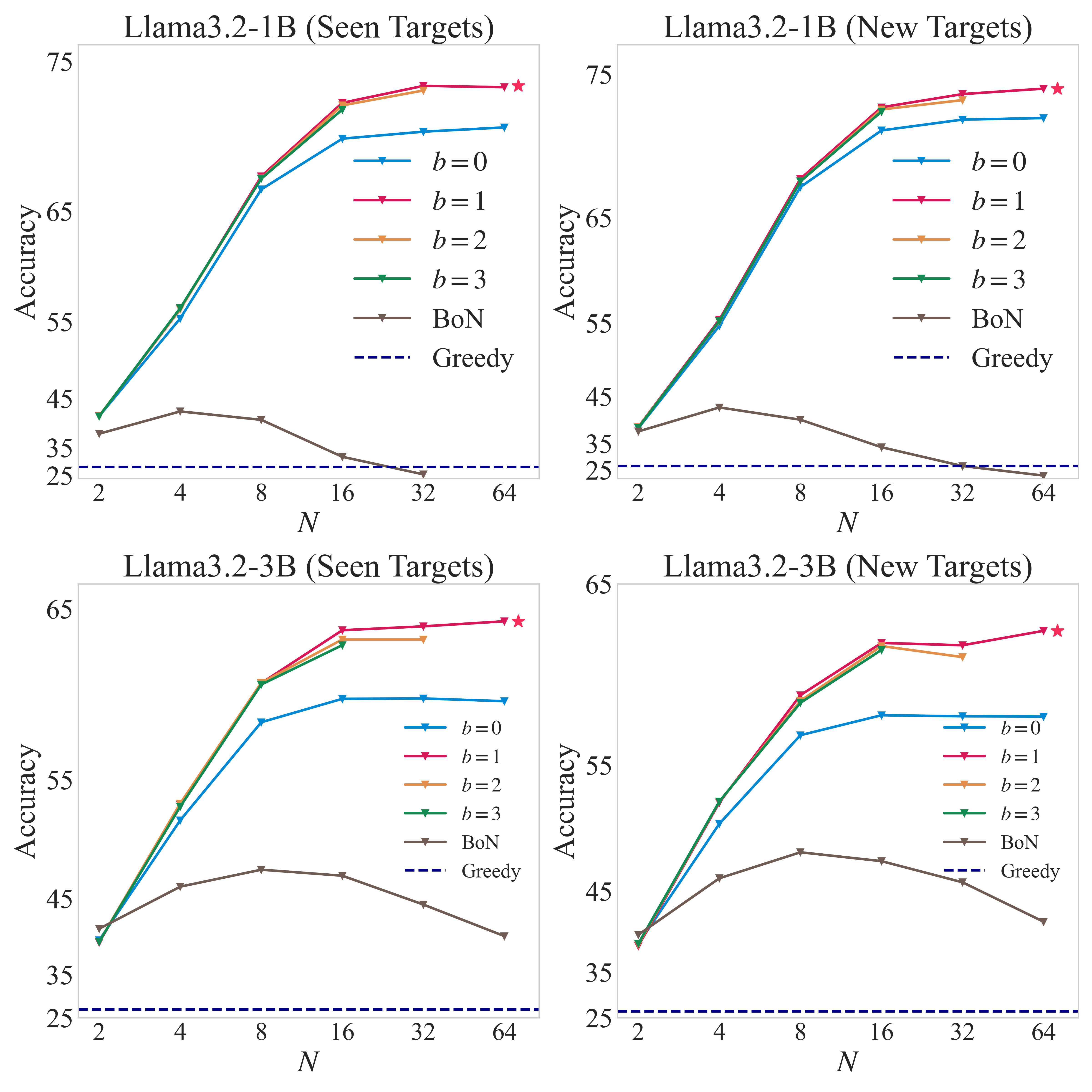
During inference, we employ a novel search algorithm that considers both depth and breadth, consisting of three steps:
- Expansion: Sample N predictions and categorize them
- Backtracking: Process backtracking containing backtrack tokens
- Selection: Choose the best reasoning path based on perplexity scores
This algorithm leverages the learned backtracking capabilities without requiring external reward models, maintaining controllable computational costs.
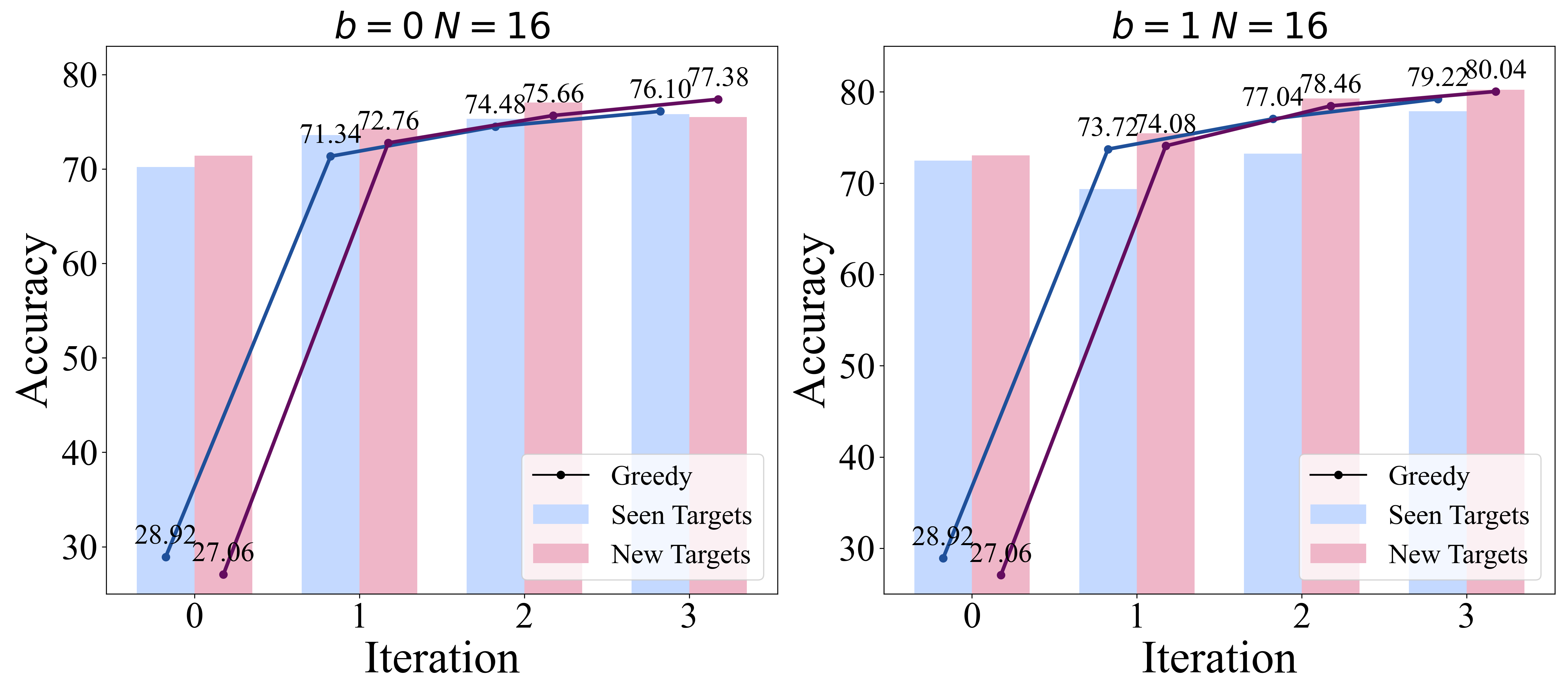
3. Self-Improvement Phase
In this stage we aim to transfer the model's slow thinking abilities to fast thinking through the self-improvement method. To achieve this, we employ an expert iteration strategy, which primarily consists of three steps: First, during the slow thinking data generation phase, we utilize the self-backtracking inference model to produce high-quality reasoning path data. Subsequently, in the expert screening phase, experts evaluate the generated data to select training samples suitable for the fast thinking model. In our experiment, we quantify the model's accuracy using an evaluator. Finally, in the fast thinking model training phase, the selected high-quality data is used to train the fast thinking model by SFT. Through this iterative optimization, we get continuous enhancement in the performance of the fast thinking model.